In this post I want to give a feel of our journey from monolith to microservices, to highlight the automation that is required to do this from a vary high level (you wont see any code samples in this post).
But first a little history
We are moving from a monolith towards a microservice EDA (Event Driven Architecture). Its been over 2 years in the making but we are getting there (although we still have 2 hefty monoliths to break down and a few databases as integration points to eliminate). We are a Microsoft shop using VS2015, C# 6, .net 4.6, NServiceBus and plenty of azure services. I'm sure you have read elsewhere that you don't move towards micro-services without adequate automation, well we have invested heavily in this in the last few years and its now paying off big time. It feels like that at the moment we have a new service or API deployed to prod every other week.There are many benefits to a microservice style of architecture of which I'm not going to list them all here, this post is more about automation and tooling in the .Net landscape.
The tools are not the job
Sometimes you get complaints that you are spending too long on DevOps related activities. That 'the tools are not the job' implying that you should be writing code not tooling around the code!! That you should be delivering features not spending so much time getting things into production!! This might have been true in the good old days when you had one monolith, maybe two, with shared databases. It used to be easy to build it on your dev machine and FTP the build up to 'the' live server (better yet MSDeploy or publish from visual studio). Then just hack around with the config files, click click your done. In those days you could count on Moore's law to help your servers scale up as you increased load, you accepted the costs of bigger and bigger servers if you needed them.But in this modern era scaling out is the more efficient, and cheaper solution especially with the cloud. Small services enable you to scale the parts of the system that need it rather than the whole system. But this architectural style comes at a cost, imagine hand deploying your service to each node running your software (there could be tens)!
We have currently over 70 core services/apis and over 50 shared libraries (via nuget). we run operations in 2 different regions each with a different configuration, different challenges and opportunities. Each region has a prod and preprod environment. We have a CI system and a test environment which is currently being rebuilt.
So 'the tools are not the job', maybe true, we do write a lot of C#, but without the tooling we would be spending most of our time, building things, deploying things and fixing the things we push to prod in a incorrect state.
Technology, Pipelines and Automation
We are a Microsoft shop dealing mainly with C#6, .net 4.6, ASP.MVC, WebApi, SQL Server, nservicebus, Azure, Rackspace and powershell, lots of powershell.We use GoCd from thoughtworks as out CI/CD tool of choice, and consequently have invested heavily in this tool chain over the last 2 years. Below is a 10,000 foot view of the 400+ pipelines on our Go server. (rapidly moving towards 500)

https://go.....com:8154/go/pipelines
Below is a rough breakdown of the different pipelines and their purposes. 01 Nuget packages - 50+
The nuget packages mainly contain message definitions used for communications between services on the service bus (MSMQ and Azure Queues). Generally each service that publishes messages has a nuget package containing the messages so that we can easily communicate between services with a shared definition.We also have a number of shared utility packages, these are also nuget packages.
These pipelines not only build and test the packages but also publish to our internal nuget feed on manual request. The whole process of getting a new package into our nuget package manager is automated, very quick, painless.
These pipelines have 3 stages:
1. Build - After every commit we build 2 artifacts, the nuget package file and a test dll. These 2 artifacts are stored in the artifact repository.
2. Test - Upon a green build the tests run.
3. Publish - If the tests are green we have a push button publish/deploy to our internal nuget feed.
02 Automation packaging - 3
This contains powershell that is needed to perform builds and deploys. These packages are deployed to a common location by Go (section 05) on to all the servers that contain agents.03 Databases - 14
We actually have over 20 databases but using CI to control the deployment of these is only just gaining traction, we are currently building this side up and so not all DBs are in the CI pipeline yet. Most are still deployed by hand using Redgate tooling, this makes it bearable but we are slowly moving to an automated DB deploy pipeline too.04 Builds - 70+
Every service/api has a build pipeline that is kicked off by a checkin to either SVN or Git. They mainly consist of 2 stages, Build and Test.Build not only compiles the code into dlls but also transforms the configuration files and creates build and test artifacts along with version info files to enable us to easily see the version of the build when it is deployed on a running server.
Test usually consists of two stages, unit and integration. Unit tests don't access any external resources, databases, file systems or APIs. Integration tests do, simples.
Only pipelines with a green build and test stage are allowed to be promoted to test or preprod environments.
05 Automation deployment - 10+
These pipelines deploy the automation as defined in section 02 to all the go agents. Region one has 3 servers in prod and preprod so 6 agents. Region two has 2 in prod and preprod and a further 2 that contain services that are deployed to by hand (legacy systems still catching up). Then we have 2 build servers and some test servers also. All these services have dependencies automatically pushed to them when the automation (which is mainly powershell) changes. Al these pipelines are push button rather than fully automatic, we want to keep full control of the state of the automation of all the servers.06 Region one prod - 40+
07 Region one preprod - 40+
08 Region two prod - 50+
09 Region two preprod - 60+
Each Region has 2 identical environments, one for preparing and testing the new software (preprod) and one that is running the actual system (prod). They are generally the same but for a small number of services that cant be run on preprod environments (generally gateways to other external 3rd parties) But also services that are still being built and not yet on prod.These pipelines generally take one of 2 forms. APIs and services.
The deployment of said APIs and services is documented here: http://foldingair.blogspot.co.uk/2014/10/adventures-in-continuous-delivery-our.html
Since that blog article was written we have started to move more and more to Azure PAAS, primarily app services and web jobs with a scattering of VMs for good measure, but in general the pattern of deployment stands.
10 Region two test system - 60+
11 Region two test databases - 6
We are currently in the process of building up a new test system (services and databases) which is why the stages are not showing color as yet. In the end we will be deploying every piece of software every night and running full regression tests against it in the early morning to ensure everything still integrates together as it did yesterday.Totals
432 pipelines and 809 stages (This was 4 weeks ago when i started to draft out this post, i know, i know, anyway it is now 460+ pipelines and 870+ stages). I wonder if this is a lot? but if you truly are doing microservices its inevitable! isn't it?The value stream map of a typical service
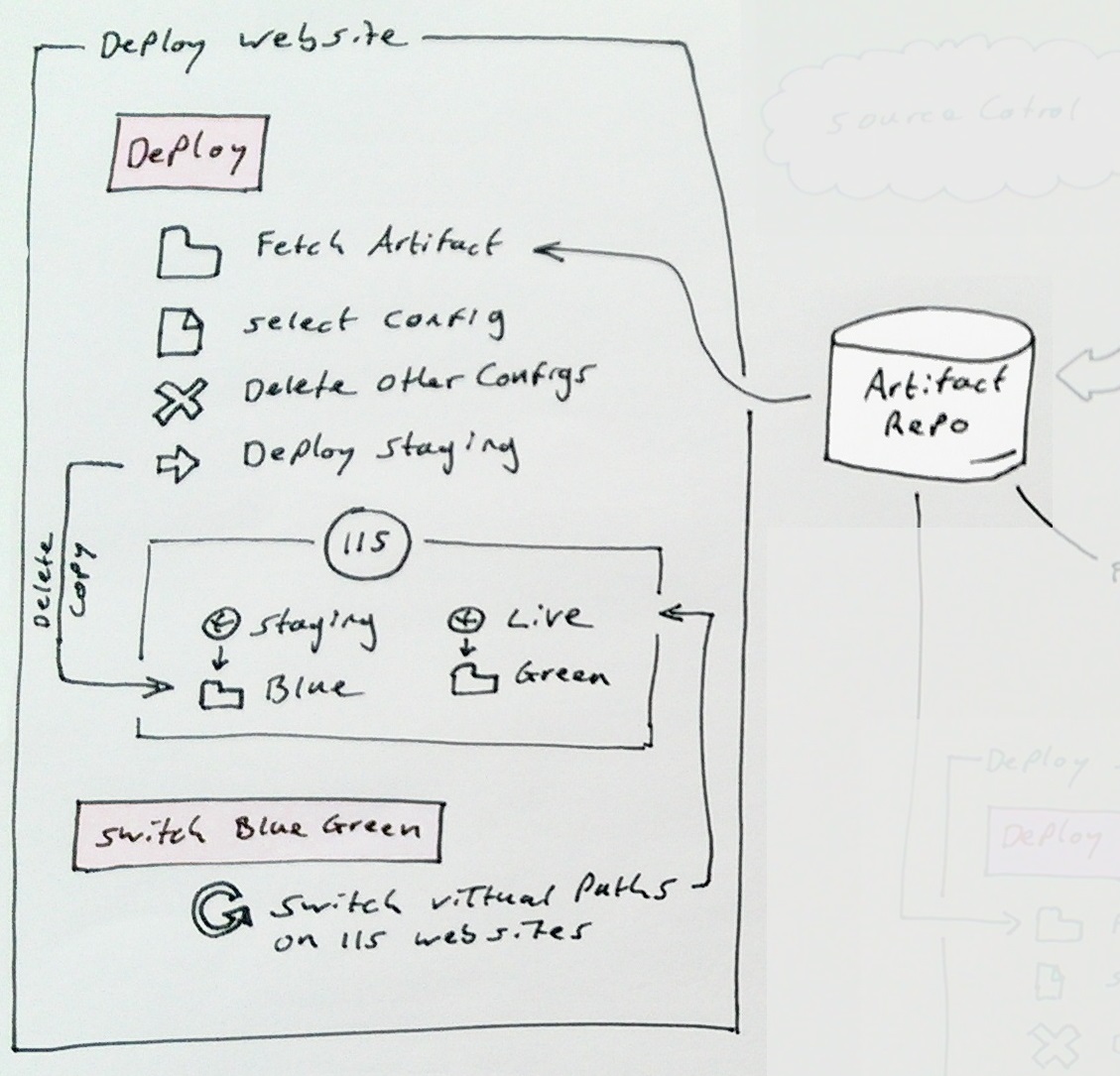
Typically one service or API will be associated with 6 pipelines and potentially pull dependencies from others via nuget or other related pipelines. A typical value stream map is shown below:
Typical Value Stream Map
The circle on the left is source control detailing the check in that triggered the build (first box on the left). Then the 5 deployment pipelines run off this, test is shown at the bottom pulling directly from the build artifact. The 4 above are the 2 regions, prod on the right pulling from preprod in the middle, that pulls the artifact from the build.
This gives us great audit functionality as you can easily see which builds were deployed to prod and when it happened. Most importantly you cant even deploy to prod unless you have first gone through preprod, you cant go to preprod if any tests failed, and the tests will only run if the code actually built.
Config
Config is also dealt with as part of the build and deploy process. Config transforms are run at the build stage and then the deployment selects the config to deploy based on a convention based approach meaning all deployments are the same (templated) and config is easy to set up in the solution itself.Whilst dealing with config in this manner its not the perfect solution it has served us really well so far, giving us confidence that all the configs of all services are in source control. We are really strict with ourselves on the servers also, we do not edit live configs on the servers, we change them in source control and redeploy. This does have its issues esp if you are only tweaking one value and there are other code changes now on trunk, but we manage. And are currently actively exploring other options that will allow us to separate the code from the config but keep the strict audit-ability that we currently have.
Monitoring and alerts
Monitoring a monolith is relatively straight forward, its either up and working or its not! With many small services there are more places for problems to arise, but on the flip side the system is more resilient as a problem wont cause the whole to come tumbling down. For this reason monitoring and alerts are vitally important.Monitoring and alerts are handled by a combination of things. NServiceBus Service pulse, splunk, go pipelines (cradiator), monitor us, raygun, custom powershell scripts, SQL monitoring, azure monitoring, rackspace monitoring and other server monitoring agents. All these feed notifications and alerts into slack channels that developers monitor on the laptops at work and on our phones out of hours. We don't actually get too many notifications flowing through as we have quite a stable platform given the number of moving parts, which enables us to actually pay attention to fail and be proactive.
Summary
With each region we are planning to bring on board there are ~ 120-150 pipelines that need to be created, luckily the templating in GoCd is very good, and you can easily clone pipelines from other regions. But managing all this is getting a bit much.I just cant imagine even attempting doing this without something as powerful as GoCd.
So the tools are not the job! maybe, but they enable 'the' job, without this automation we would be in the modern equivalent of dll hell all over again.










{kind=link}